Teaching Voice AI to Listen Better
Imagine asking a virtual assistant technology to play your favorite song, only to have a different one start playing. Or providing a verbal command to a robotic tool, and it completes another action. Now imagine you are at the doctor’s office, where accuracy and precision are essential and lifesaving, and virtual assistant technology fails to understand or transcribe the correct information based on your unique voice, medical condition, accent, first language, tone, and more.


As an AI developer and a photographer, Gerald Carter was used to the challenge of finding diversity in stock photography. What he didn’t expect to see, upon investigating how unwanted, harmful bias can impact our representation and interpretation of the world around us, was that voice assistants couldn’t understand Southern accents and that these AI-powered healthcare systems were failing to provide life-saving care based on the data they were trained on.
As the founder of Destined AI, Gerald highlights, “When I saw AI calling people ugly or comparing them to gorillas, I was shocked. But when I learned that the same biases in AI were affecting healthcare outcomes - that some people were getting life-saving diagnoses while others weren’t, simply because of their accent or appearance - I knew I had to act. This wasn’t just about technology anymore. This was about human lives.”
Hearing Every Voice and Understanding Every Accent
These firsthand experiences in how AI systems were failing diverse communities led Gerald Carter to found Destined AI, with a mission to “advance AI’s full potential and create a world where AI represents the best of humanity.”
AI runs on datasets, and Destined AI’s transformative purpose is to build AI responsibly by evaluating AI, powered by its ethically sourced and accurate data/metadata, and intentionally developed with the same rigor as AI models. Based on conversations with developers, researchers, and innovators in the community, Gerald learned that the data/metadata used in AI needs to be evaluated and improved for voice AI, which uses artificial intelligence to understand, process, and respond to spoken language, to hear every voice, understand every accent, and benefit everyone in a diverse community.
“The resources that are used to train AI models, such as audiobooks, which provide a nice pairing of speech and text, contribute to what speech-to-text transcribing systems can understand and how they respond. As a result, voice AI technologies can marginalize those that have ways of speaking, such as vowel shifts, grammar patterns, and word uses, that are not represented in this source material,” says Dr. Lelia Glass, the Director of Linguistics Program and Assistant Professor of Linguistics in the School of Modern Languages in the Ivan Allen College of Liberal Arts at Georgia Institute of Technology.
When building a robust AI dataset for Destined AI, Gerald ensured that several key elements of representation were incorporated into the process, not just the product, with a focus on building trust and accuracy. As of October 20, 2025, Destined AI has ethically sourced data from over 10,000 contributors who provided their full consent to have their voices used in both their AI models and datasets and were compensated for their participation. As a photographer working in stock photography, Gerald shares, “It was a natural part of the process for me to get consent from people to use their voices as part of the AI dataset.”

A Chorus of Voices, Clearly Heard
It is this chorus of ethically sourced content that sets the AI model and dataset apart, with its broad representation across diverse English-speaking populations, encompassing various ancestries, genders, ages, first languages, health statuses, and regions in the United States, including the intentional inclusion of participants from the South who have southern accents. This is important, as previous evaluations of voice AI datasets have found that voices from the American South, such as “those of female speakers from New Orleans, were not recognized as accurately as others by any of the major voice AI providers,” Gerald adds. To accurately transcribe and document medical conversations, speakers with conditions such as throat cancer, asthma, and allergies, which can alter the sound of a voice, are also included in the dataset.
Related inaccuracies that can show up in speech transcription are highlighted in a publication Dr. Glass co-authored in 2024. It provides several specific examples of when African American English speakers were misunderstood during automated transcription, such as “I have four kids” being transcribed as “I have four keys”. Dr. Glass adds, “This research highlights that the transcription errors were highest for older African American speakers. Similarly, speakers with Southern accents may also be more challenging to understand. In some contexts, such as medicine, it’s really important for these tools to be accurate, so we want to make sure that they work for all speakers, including those from racial minority groups and older adults, whose speech is less represented in the training data.”
The interest in reliable AI may speak for itself. Gerald shares that, “the application we made to gather consent and submit voice data via a cellphone went viral, rapidly growing from 100 to 4,500 sign-ups in just one month during its initial launch, and people mainly were hearing about this through word of mouth. And in October 2025, with the launch of Destined AI’s new custom text-to-speech model, Clarity Voice, we’ve now reached over 10,000 contributors.” As a result, a core element of this work is the ability to evaluate, benchmark, and continuously improve third-party voice AI models and agents, which are software systems that use AI to conduct conversations, using Destined AI’s equitable reinforcement learning (RL) evaluation environment.
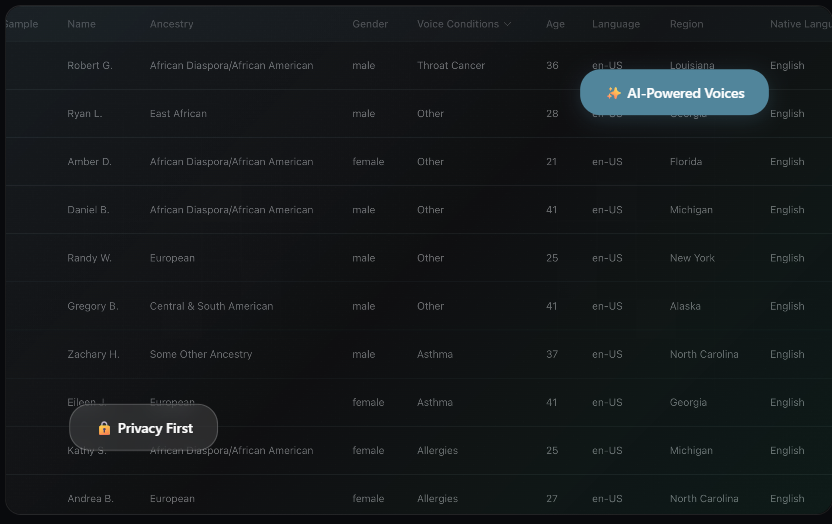
Screenshot of Destined AI dataset field. Photo by Destined AI.
Investigating Equity in AI Datasets
Just as Gerald advanced representation and human-centered imagery by creating Diversity Photos, he is inspired and dedicated to ensuring voice AI works for everyone. “I see the beauty in what makes each of us unique, and that is in our differences,” he adds. To investigate potential unwanted bias in AI, Gerald shared that the data source can reveal a lot, including copyright and privacy issues. Additionally, Gerald will explore the information included in the metadata and highlight that this is one of the most significant methods for accurately pinpointing problems with voice AI models and agents.
Destined AI ethically developed dataset includes 25-30 metadata fields, including self-identified gender, ancestry, age range, skin color (selected from the Google Monk Skin Tone Scale), first language, and voice-related medical conditions, that participants indicate and contribute as part of the process of sharing their voice and consent for use. Destined AI’s unique data and evaluation pipeline helps to advance AI’s usefulness.
“I see the beauty in what makes each of us unique, and that is in our differences.”
Experiences that Shape Us and Our Interpretation of the World

Photo by Nick Page on Unsplash
Healthcare inequity stems from a complex mix of evolving social, economic, environmental, and structural disparities that result in different health outcomes, as outlined by the National Academies of Sciences, Engineering, and Medicine’s: Communities in Action: Pathways to Health Equity. For example, the World Health Organization highlights that in many high-income countries, racial and ethnic inequities drive continued death rates from pregnancy-related causes. Without equitable and ethical design, voice AI risks reinforcing these systemic imbalances by providing uneven recognition, biased responses, or excluding specific speech patterns, thereby further skewing access to care, attention, and resources.
In our everyday lives, what we see, hear, and perceive is shaped by our past experiences, conscious thoughts, and unconscious mental shortcuts. This exploration of how everyday technologies shape our experience is a topic of research by Dr. Robert Rosenberger, a professor of philosophy in the Jimmy and Rosalynn Carter School of Public Policy in the Ivan Allen College of Liberal Arts at the Georgia Institute of Technology. In Dr. Rosenberger’s September 4, 2025, Institute for People and Technology (IPaT): GVU Lunch Lecture, “What Can Get Lost Within User Experience,” Dr. Rosenberger described to an interdisciplinary audience the concept of “technological mediation” that exists between a person and the world and how this technology transforms this relationship.
With this technological mediation in mind between patient, voice AI technology, and healthcare outcomes, it becomes clear why voice AI datasets must be evaluated for inclusivity and nuance. Only then can every person interacting with these systems receive a dignified experience and a healthcare journey shaped by equity.
Tune In So No One’s Left Out
Gerald continues to be open-minded and explores how to ensure AI models are accurate, ethical, and provide benefits to everyone. “As the future evolves and our interactions with technology become more connected, in our homes and healthcare settings alike, I am thinking about new use cases, such as those related to human-robotics interactions,” he shares.
“It is important to highlight that language is always changing, even moment to moment in a single conversation as well as over time.”
To ensure the chorus of voices within our communities is harmonious, while also allowing the soloist’s unique tone to be heard, Destined AI developed a custom text-to-speech AI model, called Clarity Voice, which focuses on aspects of pronunciation and enunciation from a diverse range of people, including rural southern and urban accents. As Gerald looks towards future projects for Destined AI, he is interested in the research of sociolinguistics specialists regarding the social use of language and regional speech patterns, to better understand the diverse accents found throughout the world.
“It is important to highlight that language is always changing, even moment to moment in a single conversation as well as over time,” says Dr. Glass, whose research focuses on recording the voices of Georgians, specifically Georgia Tech students, to better understand how Southern accents are changing over time.
With community inclusion, a symphony of resonating voices, and transparent metadata sets, we can shape how technology, such as voice AI, understands us, impacts our health outcomes, and ultimately helps define our destiny.

Photo by Helena Lopes on Unsplash